반응형
계획
- SW 정의
- 개발 범위 정하기
=> 비용예측, 기간 예측, 위험 분석 필요
- SW 개발 계획서 도출 (계획 수립의 결과 == 산출문서(deliverable))
- 일정 예측(문제(또는 개발 주제 및 범위) 정의 👉 소작업 정의 👉 순위 결정)
- 비용 예측(필요 자원(인적 자원, 기술)의 정리 및 비용 계산)
- 위험 분석(위험 요소의 판별)
- 주의점
- 시스템에 대한 충분한 이해, 변경의 여지도 있음
계획 프로세스

- 프로젝트의 범위(Scope)와 계약
- 사용자 면담, 현장관찰, 문제 정의...
- WBS(Work Breakdown Structure)
- 각 프로세스 단계에서 세부적인 일의 아이템을 구조화 시킨 그림
- 업무 정의
- 업무 기간 정의
- 작업 의존관계 정의(workflow = 일의 순서도)
- 자원 할당(인적자원)
- 마일스톤 설정(작업단계마다 나와야 할 산출물)
소프트웨어 개발 비용 예측
- 과거의 데이터를 활용한 수치 예측으로 예측
- ML 중 Regression(회귀 분석) 활용
- 과거의 데이터를 학습해 Model(수치 예측)
- 미래의 입력을 넣어 얼마가 나올지 예측
소프트웨어 개발 비용 예측의 요인(요소)
- 제품의 크기(LOC : 코드 라인 수)
- 제품의 크기가 커짐에 따라 기하급수로 비용이 늘어남
- 제품의 복잡도
- 브룩스의 법칙: 애플리케이션 개발 < 유틸리티 개발 < 시스템 프로그램 개발
- → 소프트웨어 복잡도: 개발 비용에 영향을 미침
- 프로그래머의 자질
- 코딩, 디버깅의 능력차
- 프로그래밍 언어, 응용 친숙도
- 요구되는 신뢰도 수준
- 높은 신뢰도의 소프트웨어 개발: 개발 비용의 증가
- 기술 수준(개발 장비, 도구, 조직능력, 관리, 방법론 숙달)
- 고급언어 사용: 저급 언어의 사용보다 5~10배의 생산성 증가
- 가용 시간
- Putnam “프로젝트의 노력은 남은 개발 기간의 4제곱에 반비례
계획의 상향식과 하향식

상향식
- 소요 기간을 구하고 여기에 투입되어야 할 인력과 투입 인력의 참여도를 곱하여 최종 인건 비용을 계산
- 소작업에 대한 노력을 일일이 예측
하향식
- 프로그램의 규모를 예측하고 과거 경험을 바탕 으로 예측한 규모에 대한 소요 인력과 기간을 추정
- 프로그램의 규모
- LOC
- 기능 점수(feature point)
표준 산정 공식
TRW의 2K-32K 정도의 많은 프로젝트의 기록을 통계 분석

- PM == MM : 한 사람이 한달동안 일한 양(들인 노력)
- MM = a(L*b) (Regression 회귀분석에 의한 결과)
- 위의 여러 프로젝트들의 통계분석에 의해 산출됨
- KDSI = 1000LOC : 코드 1000줄
- SW의 종류
- 유기형(organic) : 일반 응용프로그램(excel, 한글...)
- 반결합형(semi-detached) : 시스템 SW(OS, DBMS..)
- 내장형(embedded) : 특정 HW를 제어, 관리하는 SW

기본 COCOMO SW별 공식
| 노력(MM) | 기간(D) | |
|---|---|---|
| 유기형 | $PM = 2.4*(KDSI)^{1.05}$ | $TDEV=2.5*(PM)^{0.38}$ |
| 반결합형 | $PM = 3.0*(KDSI)^{1.12}$ | $TDEV=2.5*(PM)^{0.35}$ |
| 내장형 | $PM = 3.6*(KDSI)^{1.20}$ | $TDEV=2.5*(PM)^{0.32}$ |
- 예시
- CAD 시스템 예상 규모: 33360 LOC
- $PM = 3.0(KDSI)^{1.12} = 3.0(33.3)^{1.12} = 152MM$
- $TDEV = 2.5(PM)^{0.35} = 2.5(152)^{0.35} = 14.5 M$
- $N=E/D = 152/14.5 = 11 명$
- CAD 시스템 예상 규모: 33360 LOC
중간급 COCOMO(COCOMO 1)
기본 COCOMO에서 승수값을 곱하기
승수값은 아래의 표를 보고 각각의 승수값을 다 곱해나감


모든 노력 승수를 곱한다.
예: E=EAF * 2.4(32)1.05 = EAF * 91 man-months
단점
- 소프트웨어 제품을 하나의 개체로 보고 승수들을 전체적으로 적용시킴
- 실제 대부분의 대형 시스템은 서로 상이한 서브 시스템으로 구성되며 이중 일부분은 Organic Mode이고 다른 부분은 Embedded Mode인 경우도 있다.
COCOMO 2
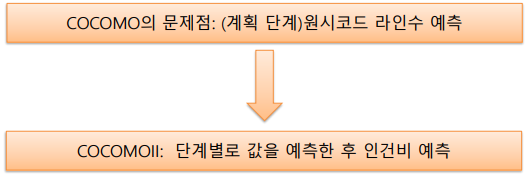

소프트웨어 개발 프로젝트가 진행된 정도에 따라 세가지 다른 모델을 제시
- 1 단계: 프로토타입 만드는 단계
- 화면이나 출력 등 사용자 인터페이스, 3 세대 언어 컴포넌트 개수를 세어 응용 점수(application points)를 계산 (AP or OP)
- 이를 바탕으로 노력을 추정
- 2 단계: 초기 설계 단계
- 자세한 구조와 기능을 탐구 (Function Point)
- 3 단계: 구조 설계 이후 단계
- 시스템에 대한 자세한 이해
초기 예측 요구사항 분석 단계, prototyping 단계, Application (object) Point
AP == OP (SW 개발 프로젝트 복잡도 측정 방법 중 하나)
생산성 : 1MM = 13AP
- The number of separate screens (화면 개수)
- The number of reports (보고서 개수) : 의사결정을 위해 받아봐야 하는 결과물
- The number of program modules (components) that must be developed to supplement the database code (3 세대 언어 컴포넌트 개수) : UX,UI에서 컴포넌트(메뉴, 버튼 등의 개수)
- Object Point (OP) = 화면# * 가중치1 + 보고서# * 가중치2 + 컴포넌트# * 가중치3
- 5 * 2+3 * 8 +4 * 10=10+24+40 = 74
- New Object Point (NOP) = OP * (100-Reuse)/100
- $NOP = 74 (100-20)/100=74*0.8=59.2$
- PM NOP/PROD
- PM = 59.2/13=4.554"
- Object Point (OP) = 화면# * 가중치1 + 보고서# * 가중치2 + 컴포넌트# * 가중치3
기능 점수(function points)

- 소프트웨어 규모를 측정하는 방법
- 기능적 요구 사항이 중심이 되는 측정 방법
- 소프트웨어의 요구 사항 복잡도를 측정
- 구현 관점 아닌 사용자 관점의 요구 기능을 정량적으로 산정
- 측정의 일관성 유지를 위해 개발 기술, 개발 방법, 품질 수준 등은 고려하지 않음
- 소프트웨어 개발에 사용되는 언어와 무관
- 정확한 라인수는 예측 불가능
기능점수

- 데이터 기능
- 내부 논리 파일(Internal Logical File) : 내 SW에 직접 탑재되는 데이터(DB, 이미지..)
- 개발 대상 SW가 직접 생성/관리하는 데이터
- 사용자가 등록/수정/삭제/조회를 하기 위한 대상
- 데이터베이스 테이블, 시스템 내부에서 다루는 파일 등
- 외부 연계 파일(External Interface File)
- 측정 대상 SW에서는 참조만 하고, 외부 다른 SW가 관장하는 파일
- (예)환율정보
- 측정 대상 SW에서는 참조만 하고, 외부 다른 SW가 관장하는 파일
- 내부 논리 파일(Internal Logical File) : 내 SW에 직접 탑재되는 데이터(DB, 이미지..)
- 트랜잭션 기능 : 사용자 입장(사용자가 시스템 사용과정에서 사용복잡도)
- 외부 입력(External Input)
- 대상 SW의 ILF (DB 또는 File)에 데이터를 등록하거나, 수정·삭제하는 것
- (예)학생 정보 등록, 수정, 삭제
- 대상 SW의 ILF (DB 또는 File)에 데이터를 등록하거나, 수정·삭제하는 것
- 외부 출력(External Output)
- 계산하는 로직을 거쳐 데이터나 제어 정보를 사용자에게 reporting하는 기능
- 수학적 계산 로직이 하나 이상 존재하며 그에 따른 파생 데이터도 존재
- (예)학생 학점 조회, 통계 리포팅 등
- 외부 조회(External inQuiry)
- 단순히 ILF, EIF의 데이터를 가져와서 별도의 가공 처리 없이 그대로 출력하는 대화식 기능
- (예) 학생 주소 검색, 학생 정보 조회
- (비교) External Output: 별도의 가공을 수행하는 로직(알고리즘)이 존재
- 단순히 ILF, EIF의 데이터를 가져와서 별도의 가공 처리 없이 그대로 출력하는 대화식 기능
- 외부 입력(External Input)
FP 계산
- 기능 요소별 개수 파악
- 기능 요소별 복잡도(가중치) 반영
- GFP : Gross Function Point
- 처리 복잡도 보정계수 반영
- PCA : Processing Complexity Adjustment
- FP 계산 = GFP * PCA
GFP

)

PCA
0~5의 가중치를 적어서 아래의 식에 대입하여 구함


📌 정리
- 5 가지 기능 분야에 해당되는 개수를 파악
- 5 각 기능에 대한 복잡도(단순, 중간, 복잡)를 결정
- 각 기능 분야의 개수와 복잡도 가중치를 곱하여 총 기능 점수(GFP)를 구한다.

- 14개의 질문을 이용하여 각 처리 복잡도의 정도에 따라 0에서 5까지 할당한다.
- 처리 복잡도 보정계수(PCA)를 다음 식을 이용하여 구한다.
- 다음 식에 넣어 기능 점수를 구한다.

실제 예시
공식암기는 필요없음

COCOMO 2
2단계 : FP
3단계 : FP + LOC까지 고려(상세설계 단계)
총 라인수 = FP * 원하는 언어의 1점 당 LOC
ex) 100FP가 요구되는 SW, C언어 개발 => 100 * 150 = 15000LOC
M = a*L^b
개발 노력
- FP만 산정한 경우: 개발 노력 (MM) = FP/생산성(FP/MM)
- LOC 산출 가정: 개발 노력 (MM)= LOC/생산성(LOC/MM)
일정 계획(Scheduling)
개발 프로세스를 이루는 소작업(activity)를 파악하고 순서와 일정을 정하는 작업
- 개발 프로세스 모델의 결정 (waterfall, v ...)
- 소작업, 산출물, 이정표 설정
작업순서
- 작업분해 (Work Breakdown Structure) - WBS
- 소작업의 구조도
- CPM (Critical Path Method) 네트워크 작성
- 최소 소요 기간을 구함
- 간트 (Gannt) 차트 도출
WBS(소작업의 계층적 구조)

- 프로젝트 목표를 달성하기 위해 필요한 작업을 세분화한 결과
- 프로젝트 구성 요소들을 계층 구조로 분류
- 프로젝트의 전체 범위 정의
- 프로젝트 작업을 세분화
CPM
WBS로 소작업과 해당 소작업을 하기위해 필요한 선행작업, 소요기간을 정리해서 그래프로 만든것
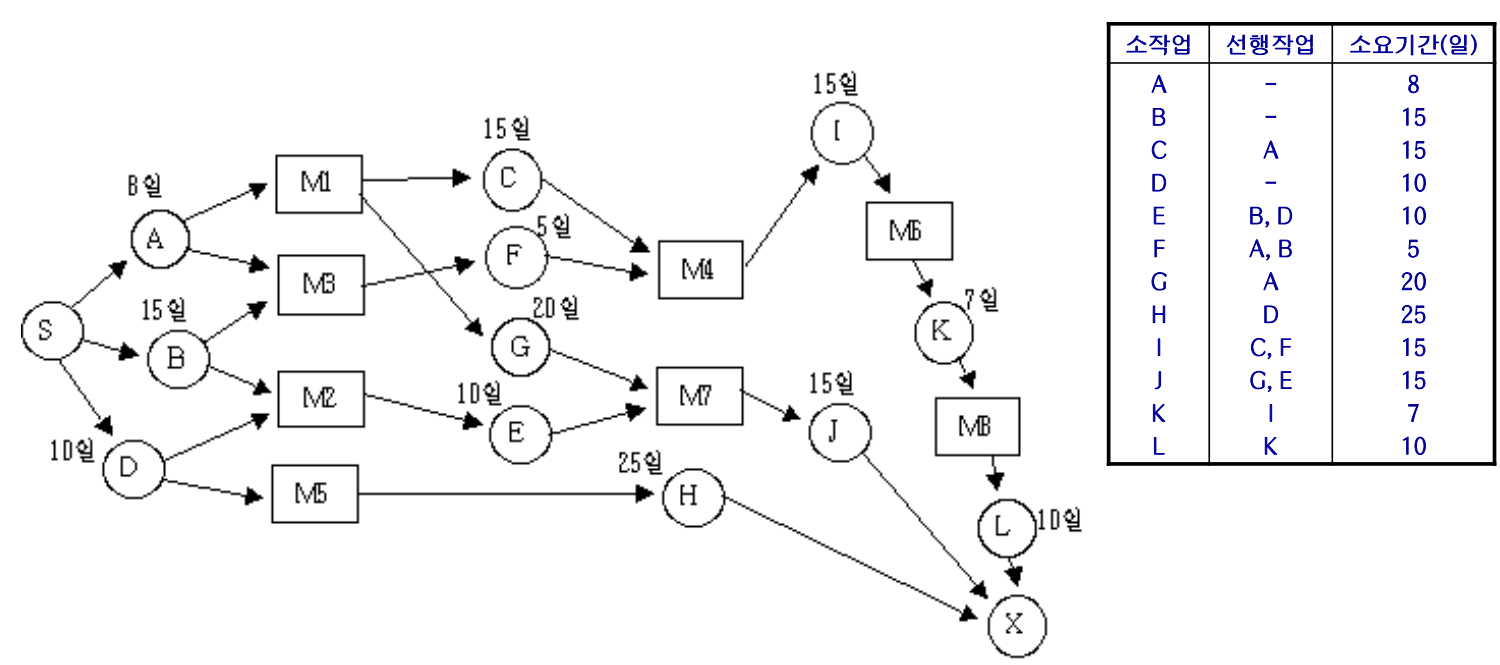
CPM 네트워크 활용
- 프로젝트를 완료할 수 있는 최소 기간의 산정
- 완료 기간을 맞추기 위해서는 각 작업을 언제 시작하고 완료해야 하는지 산정
- 전체 프로젝트가 지연되지 않으려면 어떤 작업에 특히 주의를 기울여야 하는지?
- 전체 프로젝트 완료 기간을 단축하기 위해서는 어떤 작업들을 단축하는 것이 가장 경제적인지? 등 에 대한 해답을 줌
임계 경로(Critical Path)
최대빠른착수일(earliest start time) = 늦은착수일(latest start time)
- 이 경로에 있는 작업이 지체가 되면 전체 프로젝트 개발 지연을 초래함
- 아래 조건을 만족하는 작업들의 경로
- 최대빠른착수일(earliest start time) = 늦은착수일(latest start time)
Earliest Start Time
- 가능한 빨리 시작할 수 있는 시간으로, 선행 작업이 완료되었을 때 해당작업을 시작할 수 있는 가장 빠른 시 점
- A, B, D는 선행작업이 필요가 없어서 EST가 0
- C는 A가 선행되어야 함. 따라서 EST는 A가 끝난 이후인 8

Latest Start Time
EST가 가장 큰 값을 가지고 계산(55)
백트래킹 방식
- 어떤 작업을 늦어도 시작해야 하는 시간, 즉 가장 늦게 시작할 수 있는 시간
- 이 시간에 시작하지 않으면(이 시간보다 늦게 시작하면) 총 일정이 지연
- L은 10일 걸리므로 55-10 = 40
- LST가 2개이상 나오게 되면 LST가 작은값을 선택하면됨

마무리로 각 작업을 언제 시작하고 완료해야 하는지 산정
Slack Time
LST-EST
- 여유시간
- B는 3일정도 작업이 지체되어도 괜찮음

간트 차트(Gantt)

- 소작업별로 작업의 시작과 끝을 나타낸 그래프
- Slack time 포함
- 간트차트를 보고 개인별 일정표 정함
실제 예시

- 검정색 부분은 Slack Time
프로젝트 팀 조직
조직의 구성
- 소프트웨어 개발 생산성에 큰 영향
- 작업의 특성과 팀 구성원 사이의 의사교류
프로젝트 팀 조직 정의
- 역할과 책임이 어디에 있는가 ?
- 어떤 통로로 정보가 전달되고 결정되는가 ?
- 어떻게 갈등을 해소할 것인가 ?
팀 역할 나누기
- 프로젝트 관리자(project manager)
- 시스템 운영자(system administrator)
- 시스템 분석가(system analyst)
- 시스템 개발자(software engineer)
- 데이터베이스 엔지니어(database engineer)
- QA 관리자(QA manager)
- 기술 지원(technical support)
- 하드웨어 엔지니어(hardware engineer)
- 웹 개발자 및 디자이너
직능별 조직

- 서로 다른 부서가 한 프로젝트의 다른 단계에 들어와 작업을 수행
- 요구사항분석팀은 요구사항분석만, 개발팀은 개발만 하는 방식
- 팀원은 한 부서에 소속, 프로젝트의 협력은 부서별로
프로젝트별 조직

- 직능별 개발자들이 프로젝트에 배정
- 요구사항분석, 설계. 코딩을 각 프로젝트 팀별로 전부 다 수행해야함
- 프로젝트별 협력을 해당 팀 내에서 함
- 의사 전달 경로가 짧으며 인력, 진도 등 프로젝트 관리가 수월
매트릭스 조직

- 직능별 조직의 관리자가 프로젝트 책임을 맡고 직능별 조 직 부서에 소속된 개발자가 프로젝트에 참여
- 프로젝트가 생길때 마다 설계팀에서 몇명 추출, 구축팀에서 몇명 추출해서 팀을 만들어 주는것
리스크 관리
리스크 관리의 목적
- 리스크 발생 가능성 최소화
- 리스크 발생시 영향도 취소화

리스크 파악
리스크 찾는 방법

- 회의
- 문서 분석
- 리스크 분할 구조, 체크리스트
- 유추
리스크 등록
- 리스크 파악에서 우리 프로젝트에 해당하는 리스크를 등록
리스크 평가
확률
- 영향도에 따라 평가하고 우선순위를 매김
- 확률과 리스크가 발생했을 때 미치는 영향이 우선 순위 좌우
- 정성적 방법
- 확률을 모를 때
- 가로는 발생한 리스크의 영향도(impactness), 세로는 리스크 발생 가능성(확률)
- 오른쪽, 위일수록 리스크가 많음
- E => H => M => L 순으로 리스크 구분

리스크 관리
- 위험 요소를 해소하기 위한 방법(spiral 모델)을 강구하고 프로젝트 실 행하는 동안 이를 적용
- 방법
- 리스크를 피하기 위하여 계획을 변경
- 책임을 다른 기관에 맡김
- 프로토타이핑
- 유능한 인재를 등용
- 3자와 협업
프로젝트 계획서
Planning 단계에서 만들어지는 산출물

- 핵심은 비용, 일정, 위험관리(품질)
반응형
'소프트웨어 공학' 카테고리의 다른 글
| 소프트웨어 공학 6(설계) (0) | 2023.05.31 |
|---|---|
| 소프트웨어 공학 5(설계) (2) | 2023.05.22 |
| 소프트웨어 공학 4(요구분석) (0) | 2023.05.06 |
| 소프트웨어 공학 3(요구분석) (0) | 2023.05.06 |
| 소프트웨어 공학 1 (0) | 2023.05.06 |